Tao of the Machine
Programming, Python, my projects, card games, books, music, Zoids, bettas, manga, cool stuff, and whatever comes to mind.Last 10 archives
2004-01-17
2004-01-24
2004-01-31
2004-02-07
2004-02-14
2004-02-21
2004-02-28
2004-03-06
2004-03-13
2004-03-20
Category archives
bettas
books
CCGs
Charm
esoterica
Firedrop
games
general
ideas
internet
Kaa
linkstuffs
Lisp
manga
music
Mygale
Nederland
nostalgia
programming
Python
SGI
switch
Wax
Zoids
:: Search
All posts
...by category
...by date

:: About me
:: Oasis Digital
:: Resume
:: GeoURL
:: RSS
:: Atom
wxPython 2.5.1.5 available
(via Kevin Altis) The latest version of wxPython, 2.5.1.5, is now available. Important links: Download, recent changes, migration guide.
Wax will have to use this version sooner or later, so I'm going to take a close look at the migration guide. It's possible that the current Wax version is the last one using the 2.4.x line.
Since 2.5.1.5 appears to be using new-style classes, it may be possible to "abstract away" the Wax event methods using metaclasses. Yes, I still think metaclasses are evil, but like the PyCon metaclasses paper suggests, there are situations where they are useful and actually make things clearer, compared to "regular" code... and this may be one of those situations. I will probably write more about this later; first I'll have to see how well Wax plays with 2.5.1.5, and make changes where necessary.
Finally...
After weeks of development, I am proud to present to you: the first C64 port of Python.
Here's a screenshot (in PNG format) of a sample interactive session:
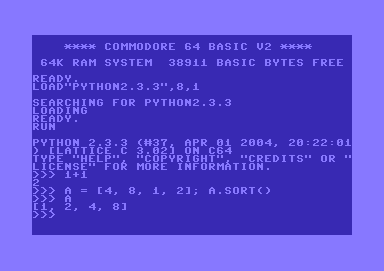
I'll upload a disk image with the binaries later today. Stay tuned.
Most popular Python projects
Via Kevin Altis: The most popular Python projects.
There is something peculiar about the current list. Most of these projects are somehow tied to Python or the Python community, except for the number one, BitTorrent. People download it because they want access to torrents, not because they are interested in Python. It just happens to be written in Python, but the number of downloads would probably be just the same if it was written in another language. In contrast, most of the other projects are developed and/or used by the Python community.
Maybe BitTorrent doesn't really belong on this list. To me, it just "looks weird". Not that it really matters. :-)
On the other hand, the presence of BitTorrent at the top of the list, with 1.3-1.5 million downloads a month, is proof that a really popular end-user application can be written in Python, if anybody was unconvinced.
In other news, I am in the process of registering a Sourceforge project for Wax. Not that I expect it to ever show up in this list  , but it could benefit from everything Sourceforge has to offer... mailing list, bug reports, CVS access, etc.
, but it could benefit from everything Sourceforge has to offer... mailing list, bug reports, CVS access, etc.
Taoist of thermodynamic Macho
And this is what my weblog looks like after its meaning has been eaten.
Brainstorm in een glas water
A few more thoughts about the "document database" (1, 2).
Performance problems, like slow packing and committing, are caused by the fact that the database is too large. It is too large because it contains many large documents. (Remember, 400 Mb of data, and that's only to start with.) Large databases and pickling don't match very well.
One solution might be, to keep the index and the document metadata in the database, and keep the documents (files) out of it. In other words, the repository would have a ZODB database, plus a not-quite-magic directory with files. When necessary, e.g. when editing, the program will open the desired file(s).
Drawback #1: Searching the actual data of each document will be very slow, since the whole directory tree needs to be traversed, and every file opened. While I might include this option, I hope this won't be necessary at all. Most common searches should be covered by the index and metadata search (keywords, size, date, etc). Otherwise, you can always do a grep or find on the actual files.
Drawback #2: The file structure can be changed externally. You could move files around, delete them, add new ones, all from outside the program, so the database would not be up-to-date anymore. The obvious solution is "so don't do that". There should also be a way to recheck (parts of) the directory, and update the database accordingly. If it's fast enough, users could easily import new files in bulk by dropping them into the right directory. This would be a good way to start with an existing collection of files.
Like somebody suggested (Ian Bicking?), it would also be possible to store URLs this way. The document's location would then be an URL rather than a local file. Obviously, such a document cannot be edited, but the GUI could do other things, like opening a web browser with the desired page.
Categories: Python, programming
Fun with the ZODB
Depending on one's interpretation of "fun"...
The ZODB introduction makes things seem really simple, but it turns out there's more to ZODB database management than just adding objects to a BTree and committing the changes. How could it be otherwise? :-)
As a test, I have been trying to add a fairly large directory tree to my repository... ~400 Mb, ~4500 files. The new version has two important improvements: 1) it stores text separately from metadata, and 2) it indexes the words in the text.
This indexing is done in a fairly simple way... probably highly insufficient for even the most basic search engine, but good enough for me. Or so I hope. The indexer returns all the "words" in a text, where a word is defined as the regular expression \w+. When indexing a document, we loop over its word list and add its id to a dictionary, keyed on the word. This is probably better illustrated with some code:
words = index.index(data)
for word in words:
try:
self.index[word].append(id)
except KeyError:
self.index[word] = [id]
This allows for very fast searching later. For example, all the (ids of) documents containing the word "python" can be retrieved with db.index['python']. 1) Needless to say, this is much faster than retrieving the text of all documents and searching it. The cost is that a structure will have to be maintained to hold these indexes; right now I'm using a PersistentMapping. 2)
Anyway, soon after implementing these two new features, I tried a bulk import, using the directory mentioned earlier. That was when I ran into the first problem: the FileStorage class keeps versioning and undo information around, causing the database file to be *much* larger than the original data, even taking indexing into account. For example, after doing around 700 files, the database had grown to over 3 Gb. (It's not the indexing that causes this, it also happens with indexing disabled.)
Apparently these features cannot be disabled when you use FileStorage, so I tried BDBMinimalStorage, which uses the Berkeley DB. That wasn't a success either... after adding 5 small files (adding up to ~120K), the database was 167 Mb! Maybe this kind of database always allocates a certain amount of space, I don't know. At that point, I quickly threw out the BDBMinimalStorage ("minimal"...?!) and went on to try the next thing.
The database object has a nice method called pack(), which can be used to get rid of superfluous data, including undo and versioning info. So that's what I'm using now, but -- as I suspected -- packing gets slower when the database gets bigger. That is only natural, but packing times of 15 seconds are not acceptable for an end-user app... and this is with a database size of 23 Mb; what will happen if I actually store 400 Mb of data, as I intended to do?
So, I'll have to think of something else. Indexing works very well, so does looping over the document metadata, but I haven't found the right balance between performance and database size yet.
[Update #1] All I really need is a storage type that does not do undo and versioning, so I won't (usually) need to pack. BDBStorage does not cut it. Are there any other storages?
[Update #2] It turns out that the pre-allocated 167 Mb has to do with the cache. Setting the cache size to a lower value (like a few Mb) works, but then other files start to grow disproportionally. Maybe that can be fixed too, but I'm currently looking at a different solution. See the next post.
-- Generated by Firedrop2.