Tao of the Machine
Programming, Python, my projects, card games, books, music, Zoids, bettas, manga, cool stuff, and whatever comes to mind.Last 10 archives
2004-02-14
2004-02-21
2004-02-28
2004-03-06
2004-03-13
2004-03-20
2004-03-27
2004-04-03
2004-04-10
2004-06-05
Category archives
bettas
books
CCGs
Charm
esoterica
Firedrop
games
general
ideas
internet
Kaa
linkstuffs
Lisp
manga
music
Mygale
Nederland
nostalgia
programming
Python
SGI
switch
Wax
Zoids
:: Search
All posts
...by category
...by date

:: About me
:: Oasis Digital
:: Resume
:: GeoURL
:: RSS
:: Atom
wxPython 2.5.1.5 available
(via Kevin Altis) The latest version of wxPython, 2.5.1.5, is now available. Important links: Download, recent changes, migration guide.
Wax will have to use this version sooner or later, so I'm going to take a close look at the migration guide. It's possible that the current Wax version is the last one using the 2.4.x line.
Since 2.5.1.5 appears to be using new-style classes, it may be possible to "abstract away" the Wax event methods using metaclasses. Yes, I still think metaclasses are evil, but like the PyCon metaclasses paper suggests, there are situations where they are useful and actually make things clearer, compared to "regular" code... and this may be one of those situations. I will probably write more about this later; first I'll have to see how well Wax plays with 2.5.1.5, and make changes where necessary.
Finally...
After weeks of development, I am proud to present to you: the first C64 port of Python.
Here's a screenshot (in PNG format) of a sample interactive session:
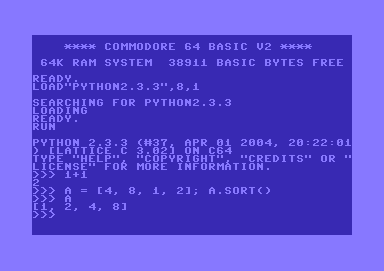
I'll upload a disk image with the binaries later today. Stay tuned.
Most popular Python projects
Via Kevin Altis: The most popular Python projects.
There is something peculiar about the current list. Most of these projects are somehow tied to Python or the Python community, except for the number one, BitTorrent. People download it because they want access to torrents, not because they are interested in Python. It just happens to be written in Python, but the number of downloads would probably be just the same if it was written in another language. In contrast, most of the other projects are developed and/or used by the Python community.
Maybe BitTorrent doesn't really belong on this list. To me, it just "looks weird". Not that it really matters. :-)
On the other hand, the presence of BitTorrent at the top of the list, with 1.3-1.5 million downloads a month, is proof that a really popular end-user application can be written in Python, if anybody was unconvinced.
In other news, I am in the process of registering a Sourceforge project for Wax. Not that I expect it to ever show up in this list  , but it could benefit from everything Sourceforge has to offer... mailing list, bug reports, CVS access, etc.
, but it could benefit from everything Sourceforge has to offer... mailing list, bug reports, CVS access, etc.
Brainstorm in een glas water
A few more thoughts about the "document database" (1, 2).
Performance problems, like slow packing and committing, are caused by the fact that the database is too large. It is too large because it contains many large documents. (Remember, 400 Mb of data, and that's only to start with.) Large databases and pickling don't match very well.
One solution might be, to keep the index and the document metadata in the database, and keep the documents (files) out of it. In other words, the repository would have a ZODB database, plus a not-quite-magic directory with files. When necessary, e.g. when editing, the program will open the desired file(s).
Drawback #1: Searching the actual data of each document will be very slow, since the whole directory tree needs to be traversed, and every file opened. While I might include this option, I hope this won't be necessary at all. Most common searches should be covered by the index and metadata search (keywords, size, date, etc). Otherwise, you can always do a grep or find on the actual files.
Drawback #2: The file structure can be changed externally. You could move files around, delete them, add new ones, all from outside the program, so the database would not be up-to-date anymore. The obvious solution is "so don't do that". There should also be a way to recheck (parts of) the directory, and update the database accordingly. If it's fast enough, users could easily import new files in bulk by dropping them into the right directory. This would be a good way to start with an existing collection of files.
Like somebody suggested (Ian Bicking?), it would also be possible to store URLs this way. The document's location would then be an URL rather than a local file. Obviously, such a document cannot be edited, but the GUI could do other things, like opening a web browser with the desired page.
Categories: Python, programming
Fun with the ZODB
Depending on one's interpretation of "fun"...
The ZODB introduction makes things seem really simple, but it turns out there's more to ZODB database management than just adding objects to a BTree and committing the changes. How could it be otherwise? :-)
As a test, I have been trying to add a fairly large directory tree to my repository... ~400 Mb, ~4500 files. The new version has two important improvements: 1) it stores text separately from metadata, and 2) it indexes the words in the text.
This indexing is done in a fairly simple way... probably highly insufficient for even the most basic search engine, but good enough for me. Or so I hope. The indexer returns all the "words" in a text, where a word is defined as the regular expression \w+. When indexing a document, we loop over its word list and add its id to a dictionary, keyed on the word. This is probably better illustrated with some code:
words = index.index(data)
for word in words:
try:
self.index[word].append(id)
except KeyError:
self.index[word] = [id]
This allows for very fast searching later. For example, all the (ids of) documents containing the word "python" can be retrieved with db.index['python']. 1) Needless to say, this is much faster than retrieving the text of all documents and searching it. The cost is that a structure will have to be maintained to hold these indexes; right now I'm using a PersistentMapping. 2)
Anyway, soon after implementing these two new features, I tried a bulk import, using the directory mentioned earlier. That was when I ran into the first problem: the FileStorage class keeps versioning and undo information around, causing the database file to be *much* larger than the original data, even taking indexing into account. For example, after doing around 700 files, the database had grown to over 3 Gb. (It's not the indexing that causes this, it also happens with indexing disabled.)
Apparently these features cannot be disabled when you use FileStorage, so I tried BDBMinimalStorage, which uses the Berkeley DB. That wasn't a success either... after adding 5 small files (adding up to ~120K), the database was 167 Mb! Maybe this kind of database always allocates a certain amount of space, I don't know. At that point, I quickly threw out the BDBMinimalStorage ("minimal"...?!) and went on to try the next thing.
The database object has a nice method called pack(), which can be used to get rid of superfluous data, including undo and versioning info. So that's what I'm using now, but -- as I suspected -- packing gets slower when the database gets bigger. That is only natural, but packing times of 15 seconds are not acceptable for an end-user app... and this is with a database size of 23 Mb; what will happen if I actually store 400 Mb of data, as I intended to do?
So, I'll have to think of something else. Indexing works very well, so does looping over the document metadata, but I haven't found the right balance between performance and database size yet.
[Update #1] All I really need is a storage type that does not do undo and versioning, so I won't (usually) need to pack. BDBStorage does not cut it. Are there any other storages?
[Update #2] It turns out that the pre-allocated 167 Mb has to do with the cache. Setting the cache size to a lower value (like a few Mb) works, but then other files start to grow disproportionally. Maybe that can be fixed too, but I'm currently looking at a different solution. See the next post.
Prototyping
Another person experimenting with Self-like prototypes for Python. Just remember that I was there first <wink>.
Of course, my code was just an experiment as well... I wonder if a "serious" prototypes package would be useful. I mean, would people actually use it? The prototype approach is very different from the regular Python class/instance model, and allows for very different constructs.
Also interesting is Prothon, and the c.l.py discussion about it. I agree that the choice of tabs for indentation is unfortunate. I also wish there were more code samples available. From what I see, I'm not sure it's all that close to Self's object model, but then again, I haven't actually programmed in Self...
Categories: Python, programming
A document database
I've always had a need for a program to store all kinds of information... notes, snippets, important mails, links, ideas, etc, but also larger texts like ebooks and manuals. You could search the repository by text, but also by keyword; a "document" would be associated with any number of keywords. (As opposed to storing a number of files in a directory tree, which is a hierarchical structure.)
A few years ago, I actually wrote the program that I had in mind, using a combination of Python and Delphi. Delphi for the GUI and database access, Python for flexible searching. In spite of that, the program was still quite rigid. And often slow, because in order to do the Pythonic search, it had to walk the database record by record.
Today, writing such a program, in pure Python, is much easier. Use the ZODB, stick objects in it, and you're all set, having all the flexibility you'll ever need. I can use Document objects that store text, plus metadata, like a title, author, creation date, etc. All this is easy to retrieve and search.
However, I'm not sure the current version scales very well. Granted, it's only a trial version, weighing in at a whopping 150 lines of code. :-) What I have so far is a rudimentary database, an import script, and an interactive console that can be used to query the database. Something like this:
>>> db <database.Database instance at 0x007DBC10> >>> db.db <BTrees._OOBTree.OOBTree object at 0x00A07390> >>> len(db.db) 4540 >>> d = db.db[2000] # just a random "record" >>> d.title 'BIGNUM.H' >>> len(d.data) 1414 >>> d.source # where it came from 'c:/cd-r/wizdom2\\prog\\c\\c-snippets\\BIGNUM.H' >>>
There are currently 4540 documents in the database, varying from small to large (over 1 Mb), totaling almost 400 Mb. Searching this database "naively" is easy but very slow:
for id, document in db.db.items():
if document.data.find("Python") > -1:
print id
This takes forever, which isn't so surprising when you think of what's going on behind the scenes (unpickling, searching a possibly large body of data, repeat 4540 times).
Optimizing this could be an interesting task. Maybe I'll need some kind of search engine functionality, like Lupy. Maybe searching can be done "smarter"; for example, there should be a simple way to search only documents of a certain size (< 10K, < 1 Mb, etc). Or maybe the actual text/data could be stored separately from the Document object, so it only gets unpickled when we really need it. (If we search for certain keywords only, then we shouldn't have to unpickle the document's text at all.) Etc.
A simpler alternative could be, to simply avoid storing large documents. Do I really need ebooks and manuals in there? Most of the time these can be found on the internet anyway. It's much more useful to store and search personal notes, mails, etc, things that would otherwise get lost in a crowded mailbox or directory.
Code will be available when I'm content about it. :-) There will be a GUI as well (written in Wax, of course), for user-friendly document management, and editing.
Adventures in writing adventures
AMK writes about interactive fiction with Python. " In text adventures, usually every single object is unique, so it's a minor irritation that you have to write classes and then instantiate the class. It would be better if you could automatically instantiate each class."
Yes, I noticed this too. A while ago, I came to the conclusion that straight OO may not be right for writing adventure games. Sure, it *seems* like a great match. You have objects for things, people/creatures, rooms, and maybe other stuff like mechanisms. An object's properties can easily be stored in attributes: lamp.on, player.inventory, etc. And mailbox.open() is the method that is called when we open the mailbox, of course. Sounds wonderful.
Except that it doesn't work all that well in practice. The problem mentioned by Andrew is just one out of many. It seems kind of redundant to have a class and an instance. Also, if you go for the mailbox.open method and friends, then there are some interesting decisions to make. How do these methods map to commands? What method is called when doing give X to Y and on what object? What about use X with Y (a Lucasarts favorite :-) ? More in this old article.
Of course, it's not *impossible* to write an adventure in Python using OO, far from it; it's just less convenient than it could be. A few ideas for ways around it:
Idea #1: Use classes, and classes only. Make all methods classmethods, all attributes class attributes. Would this work in real life? No clue. One obvious drawback is that you'll have to define the methods the usual way, *then* make them classmethods.
Idea #2: Self-style objects. This would work (assuming my code is correct, it was just something to play around with), but has an obvious drawback as well: you'll need to add methods on the fly. Something like this:
def window_open(self):
if self.open:
print "The window is already open, you dork."
else:
self.open = 1
print "You open the window."
# 'window' is a Self-like object
window.open = window_open
Both ways seem kind of unpythonic.
Lately I have been tinkering with a system that uses a mixture of OO and procedural/functional style. Some ideas:
- There are only a few classes: Room, Object, Person, Player, World (the game engine)... that's about it.
- Objects, rooms and characters in the game do not derive from these classes. Rather, to make a new Room, you create an instance of it, and stick stuff in it.
- To add code for actions, you don't add custom methods to these instances. Rather, you write a function (e.g.
get_default), associate it with a command ("get"), and register it with the game engine. - Within such functions, you can check which object (room, character, etc) you have (
if obj is apple, etc), and take appropriate action, possibly by calling other functions. - You can set an object's attributes on the fly, which is useful for setting status etc.
- A special kind of attributes are those whose name ends in
_response. This is a string that represents the default answer when a certain action is done or attempted to the object. For example:
painting.get_response = "Who would want an ugly painting like that?!" # when doing "get painting" in the game, this will be the # response
(Although normally you'll set this attribute when creating the painting instance.)
More about this in this older post. Someday I might actually try to write an adventure with this... So much time, so little energy. :-(
Observations
Via News You Can Bruise: Twisty Little Passages. I want this book. *drool*
Writing an adventure is on my to-do list, but then again, so are 100 other things...
()
Some people think the Python logging module is difficult to use. I haven't used it myself, but it certainly doesn't look too easy, especially considering that in most cases it's enough to just open a file and write to it.
It's not surprising though... I already had the impression that some Python modules/packages were designed to be complete, or to be compatible with the Java original, rather than to be Pythonic. The xml and unittest packages come to mind. Not to slight the authors of these packages, but people still write and use their own testing frameworks and XML parsers, which is a strong indicator that something's missing.
()
Sobe has a bunch of new drinks out. Black and Blue Berry. Sobe Synergy. Pomegranate Cranberry Elixir. Sobe Courage (cherry flavor). Sobe Fuerte (mango/passion fruit). Sobe Zen Tea. I haven't seen these around here... then again, Florida always gets things last.
No, I am not sponsored by Sobe.
Categories: Python, books, general
Nu even een geintje...
This code works in Lython:
(import wax) (print wax.Application) (:= app (wax.Application wax.Frame)) (app.Run)
Due to the limitations of Lython (which is at 0.1 currently), it's not very useful yet. If it supported keyword arguments, we could write
(:= app (wax.Application wax.Frame :direction "vertical" :title "Hello"))
And if it supported classes, we could subclass Frame. Then it wouldn't be very difficult anymore to write a Lython-wrapper around wxPython ("Lax"?). Allowing for the first Lisp dialect with a decent GUI. <ducking for cover>
Unrelated: I don't see car, cdr or cons in the code yet. Maybe the author doesn't plan on implementing them, if the goal is to just have a Python with Lispy syntax. I'm not sure they would be so easy to implement. Sure, (car x) as x[0] and (cdr x) as x[1:] would cover many cases, but AFAIK, Lisp's cdr doesn't make a copy, so code like this would be hard to implement:
[1]> (setq a '(1 2 3 4 5)) (1 2 3 4 5) [2]> (setq b (cdr a)) (2 3 4 5) [3]> (setf (cadr a) 42) 42 [4]> a (1 42 3 4 5) [5]> b (42 3 4 5)
(I'm running into the same problems for my PyZetaLisp interpreter... how to implement setf? Not that it's really important, since it's only a toy implementation, but one wonders...)
Extracting Windows file properties, revisited
This piece of code extracts the properties for Excel files. I'm assuming a similar solution is available for Word documents. Thanks to Ian Bicking for the BuiltinDocumentProperties tip.
def inspect_excel(filename):
app = win32com.client.Dispatch("Excel.Application")
app.Visible = 0
app.Workbooks.Open(filename)
workbook = app.ActiveWorkbook
for i in range(1, 16):
bidp = workbook.BuiltinDocumentProperties(i)
try:
value = bidp.Value
except:
value = "?"
print i, "->", value
workbook.Close()
...But what about non-MS Office files?
ZODB & ZEO docs
Looking for a ZODB/ZEO introduction, I recalled a document by Andrew Kuchling. However, I could not find that article anymore (it used to be at http://www.amk.ca/zodb/zodb-zeo.html).
Waybackmachine to the rescue: here's the article as it appeared about a year ago. I don't know why it has been removed. Maybe because there's more complete documentation available now?
Codeville
Bram Cohen releases a new Codeville build. A version control system written in Python.
Categories: Python, linkstuffs
Python and Parentheses TopicExchange
http://topicexchange.com/t/python_and_parentheses/
Aaron Brady: "Given that Python & Scheme, and Python & Lisp have been recurring memes lately, I thought it would be good to group all of these posts tegether in one place. To that end, I've created a new topic on Phillip Pearson's *excellent* TopicExchange, for people to trackback when posting about it. It's like a manual "Buzz"."
Funny this should come up... lately I've been wondering what it would be like to have a language that's a mixture of Lisp and Python. A Pythonic Lisp. A Lispy Python. A Lisp designed with Pythonic principles in mind. It could have goodies like modules and objects.
(import 'foo) ;; or maybe: (import foo) ...?
Maybe it could have special syntax for dicts, lists and object access.
(foo.bar 42) ;; sugar for: (getattr foo 'bar) (define a (range 10)) ;; a list (print a[2]) ;; sugar for: (getitem a 2) (define b sys.modules) ;; a dict (print b["os"]) ;; sugar for: (getitem a "os") (define c (create-instance Point)) (print c.x c.y) ;; sugar for: (getattr c 'x)
Maybe it could be very Pythonic. TOOWTDI, explicit is better than implicit, and all that jazz.
The language that I envision would be an independent implementation. It would not be a Lisp interpreter written in Python, or Pythonic syntax and libraries tacked onto Lisp. No, I think it should be designed from scratch, critically looking at the Lisp-vs-Python balance every step of the way.
Aside from the actual implementation, I think that the most difficult part would be, making it so that it would actually seem useful, natural, and a joy to program in... for people coming from Lisp, Python, and other languages. I'm not sure if that's possible. Sometimes I wonder if Lisp and Python, in spite of their similarities, are really based on vastly incompatible principles.
(Aside: The TopicExchange uses trackback. To make things easier, the development version of Firedrop is now capable of sending trackback pings. No, it's not available yet.  )
)
Categories: Python, Lisp
Spambayes slip-ups
I've been using spambayes for several months now. Most of the time, it does a good job. With only a little training, it sends pesky virus mails to the Junk folder. Ditto for most spam. And after the first few days, it *never* mistook ham for spam.
However, sometimes it slips up. It's no big deal, but it makes me wonder what's going on. Is the algorithm flawed, did I do something wrong (like accidentally mis-classifying certain mails), are spammers using sneaky tricks to get around the filter? The thing is that these mistakes *appear* really brain-damaged. After getting the umpteenth mail with A SUBJECT IN ALL CAPS, or the word "Nigeria" in the body, or "The Career News" as the sender, and plenty of similar mails marked as spam in the repository, you'd think that spambayes would have no problems figuring out where these belong. But for some reason, it does. Sometimes they show up as "unsure", sometimes as "ham".
The strange thing is that it classifies most mails like these as spam, but some of them somehow slip through. Except for the Career News, which is *always* marked as ham, no matter how many times I tell it it's spam. I suppose it's possible if a mail contains enough "ham" words, but it's still strange.
Do others experience the same kind of behavior? Maybe my repository is somehow messed up, and I should start with a blank slate. Or maybe it could benefit from a few simple filtering rules.
5
Hmm, PyZine issue 5...
[Update #1] This is more of sneak preview. The issue isn't out yet, but you can take a look at what will be in it.
[Update #2] Mark Pratt writes: "3 articles are available now and the remaining articles are released roughly 2 weeks apart. We publish the TOC so that people know what to expect. This is what we mean by "throughout the quarter". In addition that subscribers get access to all back Issues that beehive published including the articles from Issue 4. [...] Since we are no longer in print we are using the flexibility of publishing online to deliver the same product but with more time to spend with each author on Editing."
It's just one of those days...
It seems all I do lately is trying to pound unwilling programs into submission, with little success. Java programs that I have no clue how to start or what they require to run. C libraries that won't compile. Or Python extension modules that do compile, but don't actually work.
Maybe I have more luck tomorrow. If nothing else, I learned that compiling Python extensions with Cygwin (or MinGW) is not a walk in the park. :-/
Categories: Python, programming
Programming and creativity
Some thoughts:
1. Restrictions don't hamper creativity... they stimulate it.
2. But how do restrictive programming languages (e.g. statically typed) fit into this picture?
Would programming in Java or Pascal be more creative than programming in Python? It certainly doesn't *feel* like it... the restrictive languages get in my way, Python does not.
But in a certain way, yes -- Java and Pascal force me to find creative solutions for things that are no-brainers in Python. Most design patterns, for example. Or iterating over a list with values of arbitrary types. Unfortunately, this introduces creativity where I don't want it... solving a problem is one thing, working around the restrictions that a language imposes on you is another. So this seems like a waste of time, especially since the end result isn't any better or more interesting.
Strange. In art, restrictions fuel creativity, because it forces you to think in ways you haven't thought before. The type of restriction hardly matters -- try making a decent-looking painting with only yellow and blue, or writing a story without using the letter 'e'. Exercises like these will reshape the way you think about painting, writing, etc.
Why doesn't it work that way with programming? Using Java, Pascal, etc, certainly affect the way one thinks about programming, but is it for the better? Some may think so, but I beg to differ. Using these languages doesn't make me a better programmer, nor do they provide a better end result (everything else being equal). With a dynamic language like Python (or Lisp, etc), I get the job done, it's done faster, it's more flexible and maintainable, more open to change, and on top of that, it's fun.
Now, this is not another "Python is cool and Java sucks" rant. For Python, you can substitute your favorite dynamic/non-restrictive language, ditto for Java/Pascal and restrictive languages. No, what I'm wondering is, why don't restrictive languages fuel creativity? Or do they?
Categories: Python, programming
Dirty Python tricks
Or, abusing __getitem__ is fun.
Python Apocrypha
Hmm, I didn't know this site yet. It says it's an online supplement to the Python 2.1 Bible. Even for those who don't have the Bible (easy to get from eMule Borders or Amazon), the code snippets may be useful.