Tao of the Machine
Programming, Python, my projects, card games, books, music, Zoids, bettas, manga, cool stuff, and whatever comes to mind.Last 10 archives
2004-02-14
2004-02-21
2004-02-28
2004-03-06
2004-03-13
2004-03-20
2004-03-27
2004-04-03
2004-04-10
2004-06-05
Category archives
bettas
books
CCGs
Charm
esoterica
Firedrop
games
general
ideas
internet
Kaa
linkstuffs
Lisp
manga
music
Mygale
Nederland
nostalgia
programming
Python
SGI
switch
Wax
Zoids
:: Search
All posts
...by category
...by date

:: About me
:: Oasis Digital
:: Resume
:: GeoURL
:: RSS
:: Atom
Terug
My new weblog can be found here.
Categories: general
Weg
This weblog will be on hiatus for a while. I'll be back... eventually.
(I'm not going anywhere, I just won't update the weblog for a while, among other things. I can still be reached at the usual address.)
Laszlo Presentation Server
Laszlo Presentation Server is a system to develop rich web-based applications. It works with Flash, but because of its system-independent .lzx file format (which is based on XML), it will be capable of supporting other display formats as well.
For a quick guide, see Laszlo in Ten Minutes. In the meantime, here are my first impressions:
- Writing applications using XML is straightforward and simple. I'm not really a fan of XML, but in this case it seems a natural fit. Your components are represented by XML tags. Child controls are easily added by child tags. For example, here's "hello world" in LZX format.
<canvas height="100" width="500" >
<text>
Hello, World!
</text>
</canvas>
- Running an .lzx application is easy. Simply drop the file where LPS can see it, and point your browser to it. (Of course the application server needs to be running.)
- There are some nice features, like floating windows, easy drag & drop, easy editing, debugger, etc.
- There are data-aware controls, but most of the examples use XML datasets. Attaching them to a "real" database is possible, but not very straightforward. I would like to connect to a database directly; Laszlo however seems to depend on server-side techniques, like JSP, ASP or CGI. Also, whatever tool or technique is used, it still needs to pass data as XML.
- For more programming power, you can define classes and methods (in XML). You can also mix LZX code with JavaScript etc.
- While most of the GUI stuff is as you would expect it, there are some unusual features. For example, let's say you have a list of addresses. You edit the address by clicking it, after which an edit view appears under the original line, moving all the following addresses down. To see what I mean, see the section about data-driven applications.
- The application server output window sometimes gives helpful hints. For example, I tried modified the "hello world" example so it would show a bigger font. Without looking up the reference for the
texttag, I changed it to<text size="10">. When running it, the program ran as usual (without errors), but this appeared in the output window:
hello.lzx:2:20: attribute "size" not allowed at this point; ignored
hello.lzx:2:20: found an unknown attribute named "size" on element "text", however there is an attribute named "fontsize" on class "text", did you mean to use that?
- It's just too slow for my computer. Granted, I don't have a high-end box (900 MHz Intel Celeron, 256 Mb), but still. Apparently a lot of horsepower is necessary to run this smoothly, which you would expect from a server, I guess. Running it with IE seems faster and more stable than with Firebird, but loading times are often very slow with both browsers. Not to mention the fact that it hogs memory. (These problems might be related to the fact that it uses Java.)
All in all, a promising system. It's easy to write powerful programs that are pleasing to the eye. You'll need something better than my computer, though. :-)
Categories: internet, programming
Wax 0.2.0 released
I just finished updating Wax to work with wxPython 2.5.1.5. As the migration notes warn, this new wxPython version breaks some existing code, and I did indeed have to change a number of things in Wax, although the breakage wasn't *extremely* bad. Some of the things I noticed:
- Using
wx.NULLto indicate that a Frame has no parent does not work anymore. UseNoneinstead. This affected Frame, FlexGridFrame and GridFrame. - Some DC methods broke; use a (x, y) tuple or the methods ending in *XY.
wx.TreeView.GetFirstChildapparently changed its number of parameters.wx.Sizer.Addnow takes a tuple (width, height) or a component, which actually made the Wax code a bit easier.- Something strange: in a Notebook, when you change the page or open a new one, the window in that tab does not automatically take focus anymore. Maybe this is a problem in my own code, maybe not.
- The "choose directory" dialog has changed. (Don't know if this affects the interface; are there additional flags?)
It's possible that some of these things, like the wx.NULL issue, have been deprecated for a while... I don't know. :-)
It's also quite possible that I've overlooked some changes, so use this version with caution, and don't be too surprised if 0.2.1 will be released quickly. Also note that Wax 0.2.0 will not work with wxPythons older than 2.5.1.5. (I suppose you could hack it to make it work, but that is not recommended... in fact, the whole point of this 0.2.0 release is compatibility with 2.5.1.5.)
Downloads in the usual place. Bug reports welcome at the usual address.
wxPython 2.5.1.5 available
(via Kevin Altis) The latest version of wxPython, 2.5.1.5, is now available. Important links: Download, recent changes, migration guide.
Wax will have to use this version sooner or later, so I'm going to take a close look at the migration guide. It's possible that the current Wax version is the last one using the 2.4.x line.
Since 2.5.1.5 appears to be using new-style classes, it may be possible to "abstract away" the Wax event methods using metaclasses. Yes, I still think metaclasses are evil, but like the PyCon metaclasses paper suggests, there are situations where they are useful and actually make things clearer, compared to "regular" code... and this may be one of those situations. I will probably write more about this later; first I'll have to see how well Wax plays with 2.5.1.5, and make changes where necessary.
Finally...
After weeks of development, I am proud to present to you: the first C64 port of Python.
Here's a screenshot (in PNG format) of a sample interactive session:
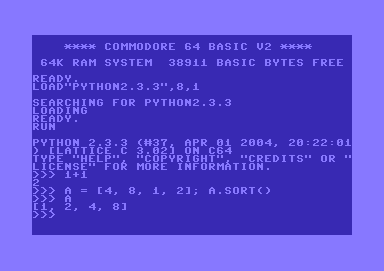
I'll upload a disk image with the binaries later today. Stay tuned.
Most popular Python projects
Via Kevin Altis: The most popular Python projects.
There is something peculiar about the current list. Most of these projects are somehow tied to Python or the Python community, except for the number one, BitTorrent. People download it because they want access to torrents, not because they are interested in Python. It just happens to be written in Python, but the number of downloads would probably be just the same if it was written in another language. In contrast, most of the other projects are developed and/or used by the Python community.
Maybe BitTorrent doesn't really belong on this list. To me, it just "looks weird". Not that it really matters. :-)
On the other hand, the presence of BitTorrent at the top of the list, with 1.3-1.5 million downloads a month, is proof that a really popular end-user application can be written in Python, if anybody was unconvinced.
In other news, I am in the process of registering a Sourceforge project for Wax. Not that I expect it to ever show up in this list  , but it could benefit from everything Sourceforge has to offer... mailing list, bug reports, CVS access, etc.
, but it could benefit from everything Sourceforge has to offer... mailing list, bug reports, CVS access, etc.
Taoist of thermodynamic Macho
And this is what my weblog looks like after its meaning has been eaten.
Brainstorm in een glas water
A few more thoughts about the "document database" (1, 2).
Performance problems, like slow packing and committing, are caused by the fact that the database is too large. It is too large because it contains many large documents. (Remember, 400 Mb of data, and that's only to start with.) Large databases and pickling don't match very well.
One solution might be, to keep the index and the document metadata in the database, and keep the documents (files) out of it. In other words, the repository would have a ZODB database, plus a not-quite-magic directory with files. When necessary, e.g. when editing, the program will open the desired file(s).
Drawback #1: Searching the actual data of each document will be very slow, since the whole directory tree needs to be traversed, and every file opened. While I might include this option, I hope this won't be necessary at all. Most common searches should be covered by the index and metadata search (keywords, size, date, etc). Otherwise, you can always do a grep or find on the actual files.
Drawback #2: The file structure can be changed externally. You could move files around, delete them, add new ones, all from outside the program, so the database would not be up-to-date anymore. The obvious solution is "so don't do that". There should also be a way to recheck (parts of) the directory, and update the database accordingly. If it's fast enough, users could easily import new files in bulk by dropping them into the right directory. This would be a good way to start with an existing collection of files.
Like somebody suggested (Ian Bicking?), it would also be possible to store URLs this way. The document's location would then be an URL rather than a local file. Obviously, such a document cannot be edited, but the GUI could do other things, like opening a web browser with the desired page.
Categories: Python, programming
Fun with the ZODB
Depending on one's interpretation of "fun"...
The ZODB introduction makes things seem really simple, but it turns out there's more to ZODB database management than just adding objects to a BTree and committing the changes. How could it be otherwise? :-)
As a test, I have been trying to add a fairly large directory tree to my repository... ~400 Mb, ~4500 files. The new version has two important improvements: 1) it stores text separately from metadata, and 2) it indexes the words in the text.
This indexing is done in a fairly simple way... probably highly insufficient for even the most basic search engine, but good enough for me. Or so I hope. The indexer returns all the "words" in a text, where a word is defined as the regular expression \w+. When indexing a document, we loop over its word list and add its id to a dictionary, keyed on the word. This is probably better illustrated with some code:
words = index.index(data)
for word in words:
try:
self.index[word].append(id)
except KeyError:
self.index[word] = [id]
This allows for very fast searching later. For example, all the (ids of) documents containing the word "python" can be retrieved with db.index['python']. 1) Needless to say, this is much faster than retrieving the text of all documents and searching it. The cost is that a structure will have to be maintained to hold these indexes; right now I'm using a PersistentMapping. 2)
Anyway, soon after implementing these two new features, I tried a bulk import, using the directory mentioned earlier. That was when I ran into the first problem: the FileStorage class keeps versioning and undo information around, causing the database file to be *much* larger than the original data, even taking indexing into account. For example, after doing around 700 files, the database had grown to over 3 Gb. (It's not the indexing that causes this, it also happens with indexing disabled.)
Apparently these features cannot be disabled when you use FileStorage, so I tried BDBMinimalStorage, which uses the Berkeley DB. That wasn't a success either... after adding 5 small files (adding up to ~120K), the database was 167 Mb! Maybe this kind of database always allocates a certain amount of space, I don't know. At that point, I quickly threw out the BDBMinimalStorage ("minimal"...?!) and went on to try the next thing.
The database object has a nice method called pack(), which can be used to get rid of superfluous data, including undo and versioning info. So that's what I'm using now, but -- as I suspected -- packing gets slower when the database gets bigger. That is only natural, but packing times of 15 seconds are not acceptable for an end-user app... and this is with a database size of 23 Mb; what will happen if I actually store 400 Mb of data, as I intended to do?
So, I'll have to think of something else. Indexing works very well, so does looping over the document metadata, but I haven't found the right balance between performance and database size yet.
[Update #1] All I really need is a storage type that does not do undo and versioning, so I won't (usually) need to pack. BDBStorage does not cut it. Are there any other storages?
[Update #2] It turns out that the pre-allocated 167 Mb has to do with the cache. Setting the cache size to a lower value (like a few Mb) works, but then other files start to grow disproportionally. Maybe that can be fixed too, but I'm currently looking at a different solution. See the next post.
Prototyping
Another person experimenting with Self-like prototypes for Python. Just remember that I was there first <wink>.
Of course, my code was just an experiment as well... I wonder if a "serious" prototypes package would be useful. I mean, would people actually use it? The prototype approach is very different from the regular Python class/instance model, and allows for very different constructs.
Also interesting is Prothon, and the c.l.py discussion about it. I agree that the choice of tabs for indentation is unfortunate. I also wish there were more code samples available. From what I see, I'm not sure it's all that close to Self's object model, but then again, I haven't actually programmed in Self...
Categories: Python, programming
A document database
I've always had a need for a program to store all kinds of information... notes, snippets, important mails, links, ideas, etc, but also larger texts like ebooks and manuals. You could search the repository by text, but also by keyword; a "document" would be associated with any number of keywords. (As opposed to storing a number of files in a directory tree, which is a hierarchical structure.)
A few years ago, I actually wrote the program that I had in mind, using a combination of Python and Delphi. Delphi for the GUI and database access, Python for flexible searching. In spite of that, the program was still quite rigid. And often slow, because in order to do the Pythonic search, it had to walk the database record by record.
Today, writing such a program, in pure Python, is much easier. Use the ZODB, stick objects in it, and you're all set, having all the flexibility you'll ever need. I can use Document objects that store text, plus metadata, like a title, author, creation date, etc. All this is easy to retrieve and search.
However, I'm not sure the current version scales very well. Granted, it's only a trial version, weighing in at a whopping 150 lines of code. :-) What I have so far is a rudimentary database, an import script, and an interactive console that can be used to query the database. Something like this:
>>> db <database.Database instance at 0x007DBC10> >>> db.db <BTrees._OOBTree.OOBTree object at 0x00A07390> >>> len(db.db) 4540 >>> d = db.db[2000] # just a random "record" >>> d.title 'BIGNUM.H' >>> len(d.data) 1414 >>> d.source # where it came from 'c:/cd-r/wizdom2\\prog\\c\\c-snippets\\BIGNUM.H' >>>
There are currently 4540 documents in the database, varying from small to large (over 1 Mb), totaling almost 400 Mb. Searching this database "naively" is easy but very slow:
for id, document in db.db.items():
if document.data.find("Python") > -1:
print id
This takes forever, which isn't so surprising when you think of what's going on behind the scenes (unpickling, searching a possibly large body of data, repeat 4540 times).
Optimizing this could be an interesting task. Maybe I'll need some kind of search engine functionality, like Lupy. Maybe searching can be done "smarter"; for example, there should be a simple way to search only documents of a certain size (< 10K, < 1 Mb, etc). Or maybe the actual text/data could be stored separately from the Document object, so it only gets unpickled when we really need it. (If we search for certain keywords only, then we shouldn't have to unpickle the document's text at all.) Etc.
A simpler alternative could be, to simply avoid storing large documents. Do I really need ebooks and manuals in there? Most of the time these can be found on the internet anyway. It's much more useful to store and search personal notes, mails, etc, things that would otherwise get lost in a crowded mailbox or directory.
Code will be available when I'm content about it. :-) There will be a GUI as well (written in Wax, of course), for user-friendly document management, and editing.
oldversion.com
After this, this is a great find: oldversion.com -- "because newer is not always better". Get the good, non-bloated versions of Acrobat Reader, Winamp, ICQ and much more.
Categories: internet, linkstuffs
YPMV
YourDictionary.com: The 100 most mispronounced words.
Some comments. (Disclaimer: I am not a native English speaker, so I can only go by what I've picked up around here. "Around here" is Florida. YPMV.)
- clothes: I haven't heard anybody here actually pronounce the [th]. People seem to say [close]. This is Florida, not Britain. :-)
- duck tape: Note that there's actually a brand called Duck Tape.
- February: Again, I haven't heard anybody pronounce the first [r]. It's "feb-yoo-ary".
- herb: Apparently, if it's a name you pronounce the [h], otherwise you don't.
- mischievous: This word isn't used often, but I've heard it pronounced "mischievious". (Yes, with the extra i.)
- pernickety: According to dictionary.com, persnickety is valid as well.
- snuck: Yes, according to dictionary.com again, this *is* a word. [snuck]
- spitting image: This is valid as well.
Some more reactions to this list.
Then there's the issue of how to pronounce Nevada...
Lindows
The Lindows site does not allow users from the Netherlands, Belgium and Luxembourg:
Important Notice! Pending Lindows' appeal visitors from the Netherlands, Belgium, and Luxembourg are not permitted to access the Lindows.com website or purchase Lindows products.
Refusing to sell your products to someone is one thing, but how can you forbid someone to visit a website? I suppose you can do crafty things with filters, block certain IP ranges etc, but forbidding it seems silly, because it's a bit hard to enforce.
JKR Chat Transcript
A JK Rowling chat transcript. Contains a few hints about book six and seven. It appears that some of the popular fan theories can be put to rest. :-}
.py
I would get a .py domain name, but they're $240, and require local presence. Oh well. 
Yesterday's technology tomorrow
Via Language Log: Yesterday's technology tomorrow.
"Tomorrow's technology today. [...] And I suddenly realized that is the exact opposite of what I want. I don't want tomorrow's technology today. I want yesterday's technology tomorrow. I want old things that have stood the test of time and are designed to last so that I will still be able to use them tomorrow. I don't want tomorrow's untested and bug-ridden ideas for fancy new junk made available today because although they're not ready for prime time the company has to hustle them out because it's been six months since the last big new product announcement. Call me old-fashioned, but I want stuff that works."
The blog post goes on with a few examples: WordPerfect, Adobe Acrobat Reader, etc. Yes, I agree, it does appear that for a lot of commercial software, every upgrade is really a downgrade... it adds a lot of features you don't need, often removes features you did need, and takes more memory and hard disk space.
Acrobat Reader 6 is a good example. A few months ago, my version 5 somehow broke, so I went to the Adobe site for the latest version, which was 6. Turns out it's quite a bit slower than its predecessor, especially when starting, when it loads all this stuff that I don't need. It also changed the "find" feature, and changed some keys around, apparently arbitrarily (e.g. Ctrl+N, to go to a page number, is now Shift+Ctrl+N).
Operating systems are another, very obvious, example. Upgrading from Windows 2000 to XP gives you a few useful features and a lot of bloat, some of which is eye candy that slows the computer down. Since I got my first PC in 1991, I've needed a new one every two years, because by then it would be too slow, incapable of running the latest software, lacking in memory and hard disk space, etc. Back in the day, a new computer at least got you some real improvements: better graphics (CGA -> EGA -> VGA -> SVGA), better sound (PC speaker -> Sound Blaster), memory above the 640K limit. These days, what are the improvements? Sure, a faster processor and more memory/disk space is always nice, but aside from that it will just be the same old stuff. 3D cards? I don't need or like them, and think it's ridiculous that anno 2004 you need one to play an adventure game.
It is developments like these that sometimes make me highly dissatisfied and make me want a Mac, an SGI or an Amiga. Or make me want to go back to the time of the command line.
On the other hand, there are some benefits as well. Interpreted languages like Python have become valid tools for mainstream programming projects. That wouldn't have been possible on memory-starving, slow machines. And ironically, I can play Broken Sword 1 on the GBA emulator, because modern PCs are powerful enough to support such a thing. Bloated software wants more memory and faster processors, but has the unintended side effect of paving the way for dynamic programming languages, emulators and other niceties.
So I guess I'll just install the older versions of some software (while they still work) and enjoy some of the positive side effects of bloated software without actually using it. 
Adventures in writing adventures
AMK writes about interactive fiction with Python. " In text adventures, usually every single object is unique, so it's a minor irritation that you have to write classes and then instantiate the class. It would be better if you could automatically instantiate each class."
Yes, I noticed this too. A while ago, I came to the conclusion that straight OO may not be right for writing adventure games. Sure, it *seems* like a great match. You have objects for things, people/creatures, rooms, and maybe other stuff like mechanisms. An object's properties can easily be stored in attributes: lamp.on, player.inventory, etc. And mailbox.open() is the method that is called when we open the mailbox, of course. Sounds wonderful.
Except that it doesn't work all that well in practice. The problem mentioned by Andrew is just one out of many. It seems kind of redundant to have a class and an instance. Also, if you go for the mailbox.open method and friends, then there are some interesting decisions to make. How do these methods map to commands? What method is called when doing give X to Y and on what object? What about use X with Y (a Lucasarts favorite :-) ? More in this old article.
Of course, it's not *impossible* to write an adventure in Python using OO, far from it; it's just less convenient than it could be. A few ideas for ways around it:
Idea #1: Use classes, and classes only. Make all methods classmethods, all attributes class attributes. Would this work in real life? No clue. One obvious drawback is that you'll have to define the methods the usual way, *then* make them classmethods.
Idea #2: Self-style objects. This would work (assuming my code is correct, it was just something to play around with), but has an obvious drawback as well: you'll need to add methods on the fly. Something like this:
def window_open(self):
if self.open:
print "The window is already open, you dork."
else:
self.open = 1
print "You open the window."
# 'window' is a Self-like object
window.open = window_open
Both ways seem kind of unpythonic.
Lately I have been tinkering with a system that uses a mixture of OO and procedural/functional style. Some ideas:
- There are only a few classes: Room, Object, Person, Player, World (the game engine)... that's about it.
- Objects, rooms and characters in the game do not derive from these classes. Rather, to make a new Room, you create an instance of it, and stick stuff in it.
- To add code for actions, you don't add custom methods to these instances. Rather, you write a function (e.g.
get_default), associate it with a command ("get"), and register it with the game engine. - Within such functions, you can check which object (room, character, etc) you have (
if obj is apple, etc), and take appropriate action, possibly by calling other functions. - You can set an object's attributes on the fly, which is useful for setting status etc.
- A special kind of attributes are those whose name ends in
_response. This is a string that represents the default answer when a certain action is done or attempted to the object. For example:
painting.get_response = "Who would want an ugly painting like that?!" # when doing "get painting" in the game, this will be the # response
(Although normally you'll set this attribute when creating the painting instance.)
More about this in this older post. Someday I might actually try to write an adventure with this... So much time, so little energy. :-(
Quotable quotes
from 1986:
We make rock 'n roll. LL Cool J is rock 'n roll. Run DMC is rock 'n roll, the Beastie Boys are rock 'n roll, Public Enemy is rock 'n roll.
--Bill Adler, Def Jam/Rush Productions
That is one of the things I'm fighting for, that rap beat is viewed as rock 'n roll. It's not R&B. As a matter of fact, we have closer alliances with heavy metal than anything else.-- Generated by Firedrop2.
--Chuck D